

")
Exploring Fine-Tuning and Retrieval-Augmented Generation: Key Strategies in NLP
Introduction
In natural language processing (NLP), fine-tuning and retrieval-augmented generation (RAG) are key techniques that enhance model performance and relevance. Fine-tuning tailors pre-trained models for specific tasks, boosting accuracy and adaptability. Meanwhile, RAG integrates external data sources, enriching generative models with real-time context and factual reliability.
This exploration breaks down both approaches, showcasing their distinct advantages, practical applications, and strategic considerations for selecting the right method. By examining historical developments, core methodologies, and emerging trends, we uncover how these techniques continue to shape AI innovation.
Historical Context and Evolution
The evolution of fine-tuning and retrieval-augmented generation (RAG) in natural language processing (NLP) has been shaped by a rich historical context reflecting broader developments in machine learning and AI. As the field has progressed, these techniques have become essential tools for generating more accurate and context-aware models. The journey began in the late 20th century, with traditional methods dominating, gradually shifting toward the revolutionary adoption of deep learning architectures and the emergence of sophisticated models trained on vast datasets.
The evolution of fine-tuning and retrieval-augmented generation (RAG) in natural language processing (NLP) reflects the broader advancements in machine learning and AI. These techniques have become fundamental in creating more accurate, context-aware models.
The journey traces back to the late 20th century when traditional rule-based methods dominated. Over time, the rise of deep learning architectures and large-scale datasets revolutionised NLP, paving the way for more sophisticated and adaptable models. As the field continues to progress, fine-tuning and RAG stand at the forefront, driving innovation and enhancing the precision of AI-driven language systems.
The introduction of neural networks was a major milestone in NLP, but it was the arrival of the transformer model in 2017, introduced by Vaswani et al, that truly accelerated the adoption of fine-tuning. The transformer architecture revolutionised NLP by enabling efficient parallel processing and improving the handling of long-range dependencies in text.
This breakthrough marked a departure from recurrent neural network (RNN) architectures, which struggled with maintaining context over extended sequences. By leveraging attention mechanisms, transformers significantly enhanced the performance of NLP tasks, setting the foundation for today’s state-of-the-art language models.
Fine-tuning became a game-changer in NLP, building on advancements in transfer learning. Researchers found that adapting pre-trained models to specific datasets led to significant performance gains across a range of tasks. This breakthrough reshaped model development, allowing deep learning to be applied effectively without the need for training from scratch.
By fine-tuning models for targeted applications, businesses and researchers unlocked new levels of accuracy and relevance in areas such as sentiment analysis, translation, and conversational AI. This adaptability continues to drive innovation, making deep learning more accessible and impactful across diverse industries.
Alongside these advancements, retrieval-augmented generation (RAG) emerged as a powerful approach, blending generative modelling with real-time information retrieval. By integrating external data sources, RAG enhances a model’s ability to generate informed, contextually relevant responses.
This technique enables models to access vast repositories of knowledge, improving accuracy and factual grounding, particularly in tasks like question answering. By bridging generative AI with retrieval mechanisms, RAG represents a significant step toward more dynamic and reliable NLP applications.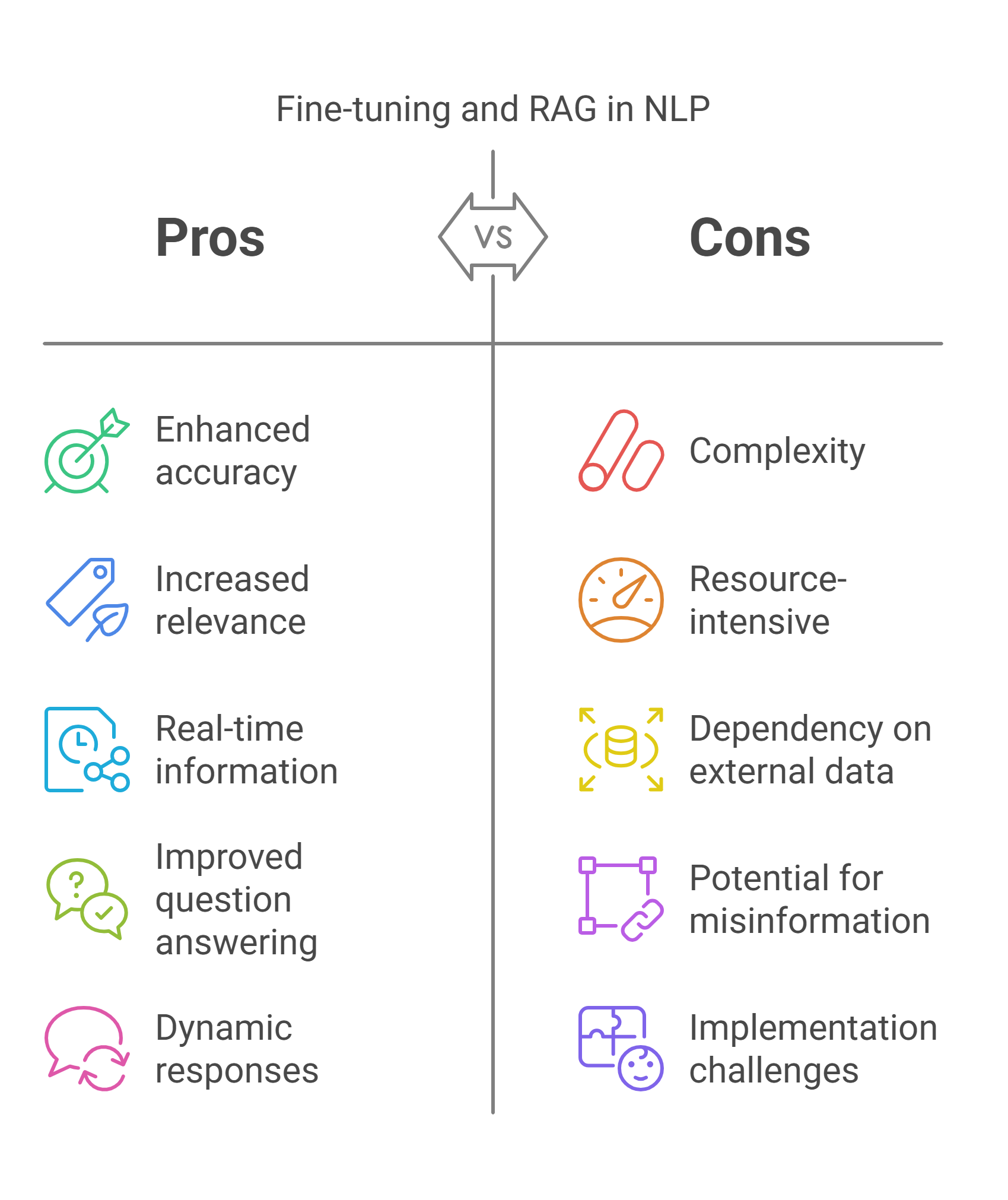
Key milestones have shaped this evolution, with models like BERT (Bidirectional Encoder Representations from Transformers), introduced in 2018, showcasing the power of fine-tuning for tasks such as classification and entity recognition. BERT’s bidirectional approach revolutionised NLP by enabling deeper contextual understanding, setting a new standard for model adaptability.
Similarly, the introduction of T5 (Text-to-Text Transfer Transformer) in 2020 further advanced fine-tuning by framing all NLP tasks as text-to-text problems. This unified approach streamlined model training across diverse challenges, reinforcing fine-tuning as an essential strategy for optimising performance in modern NLP applications.
The shift from traditional NLP methods to advanced deep learning architectures has transformed the field, with fine-tuning and retrieval-augmented generation (RAG) playing pivotal roles in enhancing model adaptability and performance. These techniques enable large pre-trained models to serve as powerful foundations, allowing for customised solutions across diverse tasks and domains.
By leveraging fine-tuning for task-specific optimisation and RAG for real-time information retrieval, NLP has evolved toward more flexible and intelligent applications. This transition underscores the growing emphasis on efficiency, scalability, and precision in machine learning, empowering businesses and researchers to develop AI-driven solutions that align seamlessly with user needs.
Deep Dive into Fine-Tuning
Fine-tuning is a key technique in NLP, enabling the adaptation of pre-trained models for specific tasks with precision and efficiency. Instead of building a model from scratch—an approach that demands extensive computational resources and vast amounts of task-specific data—fine-tuning refines an existing model, optimising it for targeted applications.
By leveraging knowledge from large, general datasets, fine-tuning accelerates model deployment, enhances accuracy, and improves performance across specialised domains. This approach makes deep learning more accessible and scalable, allowing businesses and researchers to achieve high-quality results with fewer data and resources.
The fine-tuning process involves selectively unfreezing the final layers of a pre-trained model, enabling targeted retraining with a smaller, task-specific dataset. While earlier layers retain foundational features learned during the initial training phase, the fine-tuned layers adapt to new challenges, preserving the model’s rich representational capacity.
This strategic approach allows teams to achieve high accuracy even with limited data and reduced computational demands. Models like BERT and GPT have demonstrated exceptional adaptability through fine-tuning, excelling in tasks such as text classification, sentiment analysis, and text generation. By optimising pre-trained architectures for specialised applications, fine-tuning maximises efficiency while maintaining high performance.
One of the key advantages of fine-tuning is its ability to significantly enhance task performance. For example, when fine-tuning BERT for sentiment analysis, models have demonstrated notable accuracy gains compared to those trained from scratch. In a prominent study, a fine-tuned BERT model outperformed baseline models by more than ten percentage points on multiple benchmark datasets.
This highlights the strength of fine-tuning in capturing task-specific nuances that generic training alone might overlook. By refining pre-trained models with targeted adjustments, organisations can achieve superior accuracy and efficiency, making fine-tuning an essential strategy for optimising NLP applications.
Fine-tuning also offers a significant advantage in resource efficiency. Building an NLP model from scratch demands extensive computational power and vast amounts of labelled data—requirements that can be impractical for many organisations. By leveraging pre-trained models trained on massive datasets, fine-tuning minimises resource demands while maintaining high performance.
This approach makes it feasible to deploy sophisticated NLP systems even in data-constrained environments or with limited computing power. By reducing the need for intensive training from the ground up, fine-tuning enables more accessible, cost-effective, and scalable AI solutions across various industries.
Fine-tuning is widely applicable across various NLP domains, enhancing model performance in specialised contexts. In language translation, models like MarianMT have shown remarkable effectiveness when fine-tuned for low-resource language pairs, significantly improving translation accuracy and fluency. By adapting to linguistic nuances and idiomatic expressions unique to lesser-represented languages, fine-tuning ensures more precise and natural translations.
Similarly, fine-tuning has proven invaluable in specialised fields like medical text processing. Models such as BioBERT are tailored to understand domain-specific terminology, enabling more accurate extraction of insights from clinical records, research papers, and diagnostic texts. By refining pre-trained models for targeted applications, fine-tuning drives innovation and enhances NLP’s impact across diverse industries.
Despite its advantages, fine-tuning comes with challenges—one of the most common being overfitting. When a model is fine-tuned on a small dataset, it may learn patterns too specifically, including noise and variations that fail to generalise to new data. This can result in high accuracy during training but poor performance in real-world applications.
To mitigate this risk, careful monitoring of validation metrics is essential. Techniques such as early stopping, dropout regularisation, and data augmentation help prevent overfitting, ensuring that fine-tuned models maintain robustness and adaptability across diverse inputs. By applying these strategies, teams can strike a balance between task-specific optimisation and generalisation.
Another challenge in fine-tuning is data dependency—the effectiveness of a fine-tuned model is directly tied to the quality and diversity of the dataset used. If a model is fine-tuned on a limited or biased dataset, it risks producing skewed predictions that fail to generalise across broader contexts.
Ensuring that training data is representative of the real-world distribution is crucial. Addressing issues such as class imbalance—where certain categories are overrepresented—helps prevent biased outcomes. Careful dataset curation, augmentation, and bias-mitigation strategies are essential to developing fair, reliable, and effective fine-tuned models that perform well across diverse scenarios.
Fine-tuning plays a vital role in advancing NLP, enabling the refinement of pre-trained models into highly effective, task-specific solutions. By leveraging existing architectures, researchers and developers enhance model performance, adaptability, and efficiency across diverse applications.
Through careful implementation and continuous evaluation, fine-tuning continues to push the boundaries of NLP, making AI-driven solutions more precise and accessible. As the field evolves, addressing its challenges—such as overfitting and data dependency—will be key to unlocking even greater potential, and shaping the future of intelligent language systems in innovative and impactful ways.
Unpacking Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) is a powerful framework that enhances generative models by integrating real-time retrieval systems, enabling more contextually rich and accurate outputs. By drawing from external knowledge sources, RAG overcomes the limitations of standalone generative models, ensuring responses are both informed and reliable.
RAG operates through a two-step process: retrieval and generation. In the retrieval phase, relevant documents or information snippets are sourced based on the user’s query. The generation phase then utilises this retrieved-context to produce more precise and context-aware responses. This synergy between retrieval and generation makes RAG particularly effective in tasks requiring up-to-date, factual, and nuanced outputs.
A key advantage of Retrieval-Augmented Generation (RAG) over traditional generative models is its ability to reduce hallucinations—instances where models produce plausible but factually incorrect information. While conventional models can generate fluent text, they often struggle with factual accuracy, particularly when not explicitly trained on domain-specific data.
By integrating real-time retrieval, RAG ensures that generated responses are grounded in verifiable sources, significantly improving factual reliability. This makes it especially valuable in applications where precision is critical, such as customer support, legal documentation, and knowledge-intensive domains. By drawing from authoritative sources, RAG enhances trust and accuracy in AI-driven communication.
RAG systems offer a crucial advantage in keeping information up-to-date by retrieving data from live databases, internet sources, or internal organizational repositories. This dynamic capability is particularly valuable in fields that require real-time updates, such as news reporting, financial analysis, and live event coverage.
Unlike static generative models, which rely solely on pre-trained knowledge, RAG ensures responses reflect the latest information by continuously integrating new data. This ability to access and incorporate current insights makes RAG a powerful tool for delivering accurate, relevant, and timely outputs, providing users with more reliable and context-aware information.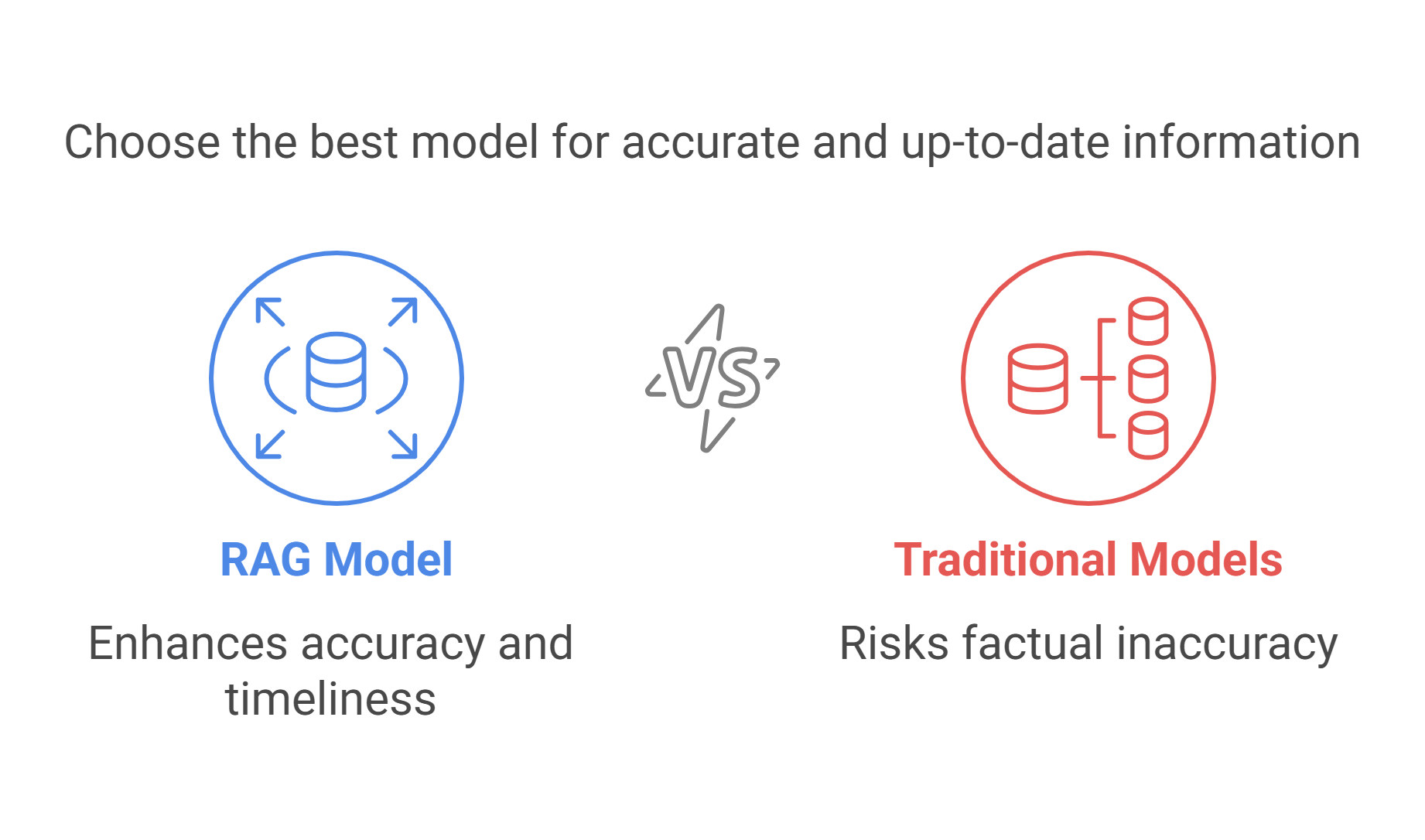
RAG’s practical applications extend across multiple domains, delivering enhanced accuracy and contextual awareness. In customer support, RAG-powered systems can significantly improve response quality by retrieving relevant knowledge bases or FAQs tailored to user queries. This ensures that automated responses are not only accurate but also detailed and informative, leading to higher customer satisfaction.
Additionally, the generative component personalises interactions, making responses feel more natural and engaging rather than robotic. By combining retrieval and generation, RAG enables customer service solutions that are both efficient and adaptive, providing users with precise, contextually relevant support.
In real-time news generation, RAG is a game-changer, enabling journalists to access and synthesise the latest information from news wires, online sources, and authoritative reports. By retrieving up-to-date content, RAG ensures that generated articles and summaries remain accurate, relevant, and reflective of unfolding events.
This capability streamlines the reporting process, reducing the time required for research while enhancing the reliability of news dissemination. By integrating retrieval with generative AI, RAG empowers media professionals to produce timely, well-informed content that keeps pace with rapidly evolving developments.
RAG excels in personalised content creation by leveraging user-specific preferences and past interactions to generate highly relevant and engaging material. In marketing, this capability enables businesses to craft personalised newsletters, targeted product recommendations, and tailored messaging that aligns with individual customer interests.
By retrieving and integrating relevant data, RAG enhances engagement and boosts conversion rates, creating a more meaningful connection between brands and consumers. This level of personalisation not only improves customer experience but also strengthens brand loyalty—an essential advantage in today’s competitive digital landscape.
While RAG offers significant advantages, it also presents challenges that must be carefully managed. One key limitation is its dependency on the quality and relevance of retrieved documents. If the retrieval system pulls outdated or irrelevant information, the generated output may lack coherence, accuracy, or contextual appropriateness.
Additionally, the dual-step process of retrieval and generation can introduce latency, as the system must first fetch relevant data before formulating a response. This trade-off between speed and accuracy is a critical consideration in real-world applications, requiring optimisation strategies such as efficient indexing, caching mechanisms, and retrieval refinement to ensure responsiveness without compromising reliability.
While RAG significantly reduces hallucinations, it does not eliminate them. Misleading outputs can still arise if the retrieval system pulls irrelevant or low-quality information or if it misinterprets user queries. The accuracy of RAG models depends on the robustness of the retrieval mechanism, making it crucial to refine these systems continuously.
To mitigate these risks, ongoing optimization of retrieval algorithms, careful dataset curation, and continuous training with diverse and high-quality sources are essential. By strengthening these components, organisations can enhance the reliability of RAG models, ensuring they generate accurate, context-aware, and trustworthy responses.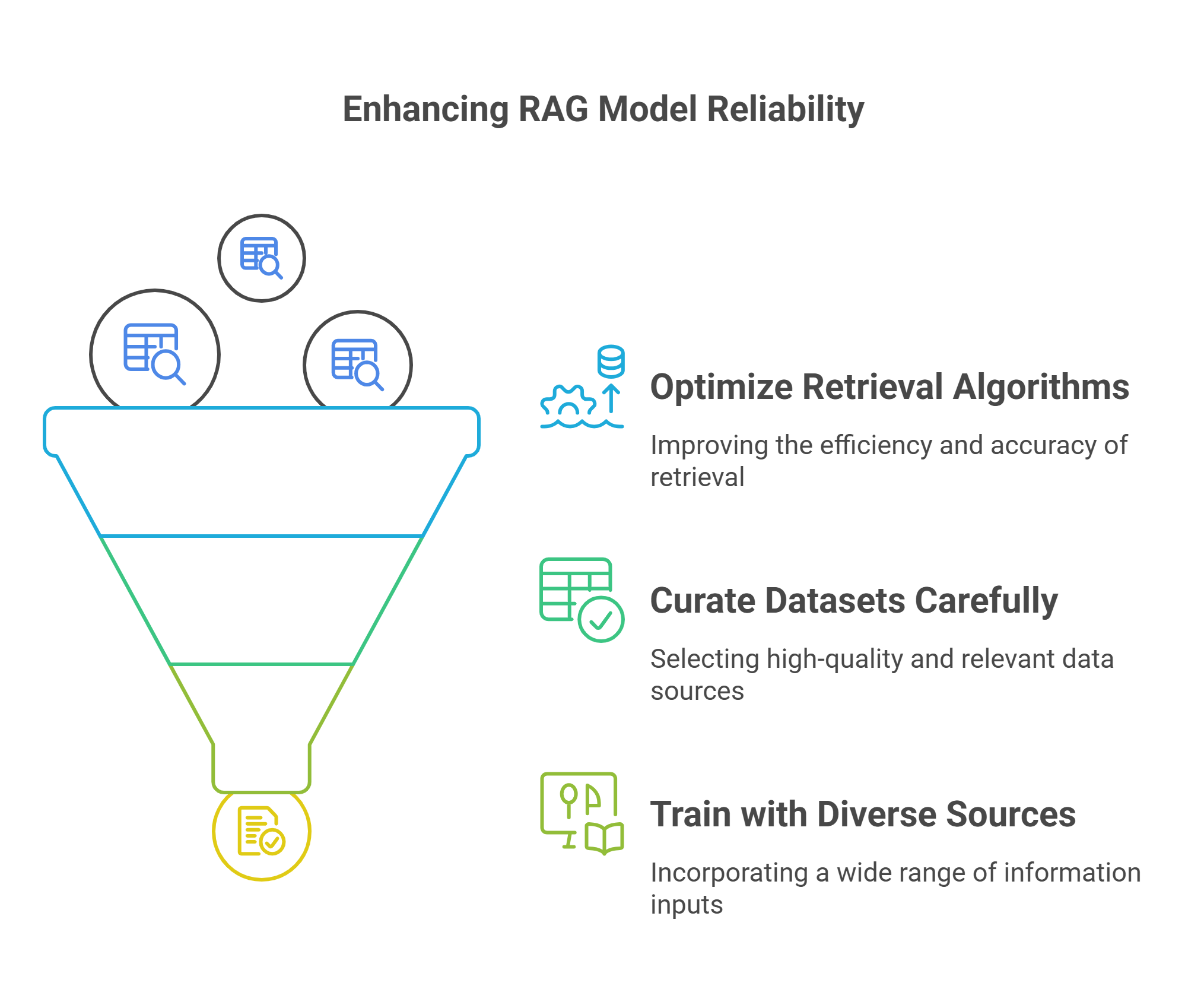
Retrieval-Augmented Generation (RAG) represents a significant advancement in NLP, seamlessly combining information retrieval with generative capabilities to enhance accuracy and contextual relevance. Its ability to produce factually grounded content and integrate up-to-date information makes it a valuable tool across diverse applications, from customer support to personalised content creation.
As organisations increasingly adopt RAG, its impact on AI-driven communication and information processing continues to grow. By addressing challenges such as retrieval quality and system latency, RAG is shaping the future of intelligent automation, enabling machines to provide more reliable, informed, and context-aware assistance in an increasingly complex digital world.
Comparative Analysis
Fine-tuning and Retrieval-Augmented Generation (RAG) are two powerful NLP techniques, each with distinct strengths and trade-offs that make them suitable for different applications. This comparative analysis highlights their advantages, limitations, and optimal use cases, providing clarity on when to apply each approach.
Fine-tuning excels in task-specific adaptation, allowing models to learn nuanced patterns from labelled datasets, making it ideal for applications like sentiment analysis, text classification, and domain-specific language processing. However, it requires substantial labelled data and can be resource-intensive.
RAG, on the other hand, enhances generative models by retrieving external information, ensuring outputs remain factually accurate and up to date. This makes it particularly effective for tasks requiring real-time knowledge integration, such as customer support, legal document generation, and news summarization. However, it depends on the quality of retrieved content and may introduce latency due to its two-step process.
By examining performance metrics—including accuracy, computational efficiency, adaptability, and factual reliability—this analysis helps practitioners determine the best approach based on project goals and constraints. Understanding the trade-offs between fine-tuning and RAG enables more informed decision-making, ensuring the development of robust and efficient NLP solutions.
Fine-tuning refines a pre-trained model by adjusting its parameters on task-specific datasets, leveraging prior knowledge to enhance performance on specialised applications. This approach allows models to retain foundational linguistic understanding while adapting to new contexts with precision.
One of the key advantages of fine-tuning is its ability to deliver high performance even with limited labelled data. In domains where annotated datasets are scarce, fine-tuned models can efficiently learn task-specific nuances, making them highly effective for applications such as sentiment analysis, text classification, and named entity recognition. When trained on high-quality datasets, fine-tuned models frequently achieve over 90% accuracy, demonstrating their strength in optimising NLP tasks for targeted use cases.
Despite its advantages, fine-tuning comes with challenges, the most notable being the risk of overfitting. When trained on a small or unrepresentative dataset, a fine-tuned model may become overly specialised, capturing patterns too narrowly and performing poorly on unseen data. This limitation can hinder generalisability, reducing the model’s effectiveness in real-world applications.
Additionally, the success of fine-tuning is highly dependent on the quality and quantity of available data. Poorly curated or biased datasets can lead to skewed outputs, making careful data selection and preprocessing essential. Implementing strategies such as regularization, data augmentation, and cross-validation can help mitigate these risks, ensuring fine-tuned models remain both accurate and adaptable.
In contrast, Retrieval-Augmented Generation (RAG) enhances traditional generative models by integrating retrieval mechanisms, enabling the system to pull relevant information from large datasets while generating coherent, context-aware responses. This hybrid approach significantly improves scalability, allowing models to handle a wide range of tasks without extensive fine-tuning.
One of RAG’s key advantages is its ability to incorporate up-to-date and domain-specific knowledge dynamically. This makes it particularly effective for applications like open-domain question answering, legal and medical document generation, and customer support, where access to extensive and evolving information is crucial. By retrieving relevant content before generating responses, RAG improves factual accuracy and mitigates the limitations of static generative models, offering a more reliable and scalable solution for knowledge-driven NLP tasks.
Despite its advantages, RAG also presents challenges. A primary limitation is its dependency on the quality of retrieved information—if the retrieval mechanism pulls irrelevant, outdated, or noisy data, the generated response may suffer in accuracy and coherence. This reliance makes optimising retrieval algorithms critical for maintaining performance and reliability.
Additionally, RAG systems can be computationally intensive, as they must first retrieve relevant content before generating a response. This dual-process structure can lead to increased latency compared to standalone generative models, making real-time applications more resource-demanding. To mitigate these challenges, techniques such as efficient indexing, caching, and retrieval optimisation are essential to balancing accuracy with speed in RAG-based systems.
To highlight where each method excels, consider sentiment analysis and conversational AI systems.
Fine-tuning is particularly well-suited for sentiment analysis, where the objective is to detect specific emotional cues within the text. Since the task is relatively narrow and well-defined, fine-tuned models can achieve high accuracy, even with limited labelled data. Their ability to learn nuanced sentiment patterns makes them highly effective in applications like customer feedback analysis, brand monitoring, and social media sentiment tracking.
On the other hand, RAG is better suited for conversational AI, where responses must integrate diverse knowledge sources in real-time. By retrieving relevant context from vast information repositories, RAG-powered chatbots and virtual assistants can generate more informed, context-aware responses. This capability is particularly valuable in domains requiring up-to-date or specialised knowledge, such as technical support, legal advisory, or healthcare guidance, where static generative models may struggle to provide accurate and comprehensive answers.
When assessing performance metrics, different evaluation criteria apply to fine-tuning and RAG, reflecting their distinct operational mechanisms.
For fine-tuning, key metrics include precision, recall, and F1 score, which measure the model’s ability to generalize effectively from a specific dataset. These metrics are particularly relevant in classification tasks like sentiment analysis or named entity recognition, where high precision ensures that relevant patterns are correctly identified, and strong recall prevents important signals from being missed. A well-optimized fine-tuned model in sentiment analysis, for example, may achieve over 90% accuracy, serving as a benchmark for task-specific performance.
For RAG, evaluation focuses on retrieval precision and response coherence, as retrieved information directly influences the quality of generated outputs. Retrieval precision measures the proportion of relevant documents retrieved, ensuring that the generative model has access to accurate and contextually appropriate data. Meanwhile, coherence and factual accuracy in generated responses are crucial for applications like conversational AI and question answering, where integrating external knowledge enhances reliability. The effectiveness of a RAG model is determined not just by how well it retrieves information, but also by how fluently and accurately that information is synthesized into meaningful responses.
Ultimately, performance metrics should align with the application’s goals—whether optimizing a fine-tuned model for high classification accuracy or ensuring a RAG system retrieves relevant data swiftly and generates coherent, factually correct responses.
In complex NLP applications, a hybrid approach combining fine-tuning and RAG can be highly effective, leveraging the strengths of both methodologies. This is particularly beneficial in domains that require deep contextual understanding alongside real-time access to external knowledge sources, such as medical diagnosis and legal document interpretation.
For example, in medical NLP, a fine-tuned model can be trained on specialized datasets to develop a deep understanding of medical terminology, patient records, and diagnostic patterns. However, since medical guidelines and research evolve rapidly, integrating a RAG component allows the model to retrieve up-to-date medical literature, clinical guidelines, or drug interaction databases, ensuring that its recommendations remain current and evidence-based.
Similarly, in legal NLP applications, a fine-tuned model can capture domain-specific semantics, understanding contracts, case law, and legal terminology. By incorporating RAG-based retrieval, the system can dynamically pull relevant precedents, legislation updates, or regulatory guidelines, enhancing legal research and document review processes.
This hybrid strategy enables practitioners to combine the adaptability of fine-tuning with the real-time knowledge integration of RAG, improving both performance and reliability. Such an approach is invaluable in fast-evolving industries, where maintaining accuracy and relevance is critical for decision-making and compliance.
Choosing between fine-tuning and RAG depends on key factors such as task complexity, data availability, and computational resources. Practitioners must evaluate project requirements carefully, weighing the trade-offs associated with each approach to determine the most effective solution.
– Fine-tuning is ideal for tasks with limited but high-quality labelled data and well-defined scope, such as sentiment analysis, classification, and domain-specific language understanding. It provides high accuracy and task-specific adaptability but requires careful dataset curation to prevent overfitting.
– RAG is more advantageous for projects that require dynamic knowledge retrievals and contextual awareness, such as open-domain question answering legal document processing, or real-time customer support. While it enhances factual accuracy and adaptability, it can introduce computational overhead and dependency on retrieval quality.
As NLP continues to evolve, staying updated on advancements in these methodologies will be crucial. Understanding their comparative strengths allows for strategic implementation, ensuring that models remain efficient, scalable, and aligned with real-world needs. Whether fine-tuning, RAG, or a hybrid approach, informed decision-making will drive successful, high-performing NLP solutions across diverse applications.
Challenges and Considerations
Implementing fine-tuning and retrieval-augmented generation (RAG) in NLP comes with both technical challenges and ethical considerations. Addressing these complexities is essential for building robust, responsible AI models that effectively serve their intended purposes while minimizing potential risks.
Technical Challenges
– Fine-tuning Risks: Overfitting, data scarcity, and domain adaptation issues can limit model generalization, requiring careful dataset curation and validation strategies.
– RAG Limitations: Dependence on retrieval quality can lead to inaccuracies if retrieved documents are outdated, biased, or irrelevant, necessitating continuous monitoring and retrieval optimisation.
– Computational Costs: Both techniques require significant resources—fine-tuning for extensive training and RAG for retrieval operations—making efficiency a key consideration.
Ethical Considerations
– Bias in Training Data: Fine-tuned models may inherit biases from their datasets, leading to skewed or unfair outcomes. Mitigation strategies include diverse dataset representation and bias auditing.
– Misinformation Risks: While RAG reduces hallucinations, it can still retrieve and propagate misleading or unverified information, emphasizing the need for source validation mechanisms.
– Data Privacy: When leveraging external repositories, RAG systems must ensure compliance with data privacy regulations, preventing unauthorized use of sensitive information.
By integrating robust evaluation methods, bias detection frameworks, and ethical AI principles, practitioners can enhance model reliability and trustworthiness, ensuring that fine-tuning and RAG implementations align with responsible AI practices.
Fine-tuning pre-trained models has become a widely adopted approach due to its efficiency in adapting general models to specific tasks. However, it comes with challenges, one of the most significant being bias in fine-tuned models.
Bias can originate from the training data, where historical or societal prejudices embedded in the dataset may lead to discriminatory outputs. Researchers have observed cases where fine-tuned models, trained on biased datasets, reinforce stereotypes or produce unfair outcomes, raising ethical concerns. This issue is particularly critical in applications like hiring algorithms, legal document analysis, and medical diagnostics, where biased outputs can have real-world consequences.
To mitigate these risks, practitioners must implement rigorous data curation strategies, including:
– Bias audits and fairness checks before and after fine-tuning.
– Diverse and representative datasets to ensure balanced learning.
– Regular model evaluations to detect and address unintended biases.
By proactively addressing bias, fine-tuned models can be made more equitable, transparent, and trustworthy, fostering responsible AI deployment in real-world applications.
Similarly, Retrieval-Augmented Generation (RAG), while enhancing generative models with external knowledge, introduces its own set of challenges—chief among them being accuracy and reliability of generated content.
Since RAG models generate responses based on the retrieved information, the quality and credibility of retrieved passages directly impact the output. If the retrieval system sources outdated, biased, or misleading content, the model may unintentionally propagate misinformation. This is particularly concerning in applications like news summarization, legal analysis, and medical recommendations, where factual accuracy is paramount.
Challenges of Fine-Tuning
Despite its advantages, fine-tuning comes with challenges, the most notable being the risk of overfitting. When trained on a small or unrepresentative dataset, a fine-tuned model may become overly specialized, capturing patterns too narrowly and performing poorly on unseen data. This limitation can hinder generalizability, reducing the model’s effectiveness in real-world applications.
Data Quality and Overfitting
The success of fine-tuning is highly dependent on the quality and quantity of available data. Poorly curated or biased datasets can lead to skewed outputs, making careful data selection and preprocessing essential. Implementing strategies such as regularization, data augmentation, and cross-validation can help mitigate these risks, ensuring fine-tuned models remain both accurate and adaptable.
Retrieval-Augmented Generation (RAG) Overview
In contrast, Retrieval-Augmented Generation (RAG) enhances traditional generative models by integrating retrieval mechanisms, enabling the system to pull relevant information from large datasets while generating coherent, context-aware responses. This hybrid approach significantly improves scalability, allowing models to handle a wide range of tasks without extensive fine-tuning.
Advantages of RAG
- Dynamic Knowledge Integration: Enables real-time access to domain-specific and up-to-date information.
- Improved Factual Accuracy: Reduces the limitations of static generative models by retrieving relevant content before generating responses.
- Scalability: Enhances performance across diverse applications like open-domain question answering, legal and medical document generation, and customer support.
Challenges of RAG
- Retrieval Dependency: If the retrieval mechanism pulls irrelevant, outdated, or noisy data, the generated response may lack accuracy and coherence.
- Computational Intensity: The dual-process structure of retrieval and generation can increase latency compared to standalone generative models.
- Optimization Requirements: Efficient indexing, caching, and retrieval optimization are essential for balancing accuracy with speed.
Comparing Fine-Tuning and RAG
Use Cases
Fine-Tuning for Sentiment Analysis
Fine-tuning is particularly well-suited for sentiment analysis, where the objective is to detect specific emotional cues within the text. Its ability to learn nuanced sentiment patterns makes it highly effective in applications like customer feedback analysis, brand monitoring, and social media sentiment tracking.
RAG for Conversational AI
RAG is better suited for conversational AI, where responses must integrate diverse knowledge sources in real time. RAG-powered chatbots and virtual assistants generate more informed, context-aware responses, making them valuable in technical support, legal advisory, and healthcare guidance.
Performance Metrics
Fine-Tuning Metrics
- Precision, Recall, and F1 Score: Measure a model’s ability to generalize effectively.
- Accuracy Benchmarks: High accuracy in classification tasks like sentiment analysis and named entity recognition.
RAG Evaluation Criteria
- Retrieval Precision: Ensures that retrieved documents are relevant and useful for generation.
- Response Coherence and Factual Accuracy: Measures how well-retrieved information is synthesized into meaningful responses.
Hybrid Approaches in NLP
Combining Fine-Tuning and RAG
A hybrid approach leveraging both fine-tuning and RAG can enhance performance in domains that require deep contextual understanding alongside real-time knowledge integration.
Medical NLP
A fine-tuned model can develop a deep understanding of medical terminology and diagnostic patterns, while RAG retrieves up-to-date medical literature and clinical guidelines.
Legal NLP
Fine-tuned models understand contracts, case law, and legal terminology, while RAG dynamically pulls relevant precedents, legislation updates, or regulatory guidelines.
Challenges and Ethical Considerations
Technical Challenges
- Fine-Tuning Risks: Overfitting, data scarcity, and domain adaptation limitations.
- RAG Limitations: Dependence on retrieval quality can lead to inaccuracies.
- Computational Costs: Both techniques require significant resources.
Ethical Considerations
- Bias in Training Data: Fine-tuned models may reinforce biases present in datasets.
- Misinformation Risks: RAG systems can retrieve and propagate misleading information.
- Data Privacy: Compliance with data regulations is essential when using external repositories.
Conclusion
Choosing between fine-tuning and RAG depends on key factors such as task complexity, data availability, and computational resources. Practitioners must weigh trade-offs to determine the most effective solution.
- Fine-Tuning: Best for tasks requiring domain-specific learning with high-quality labelled data.
- RAG: Ideal for projects requiring dynamic knowledge retrieval and contextual awareness.
By staying informed on advancements, practitioners can strategically implement these methodologies to build efficient, scalable, and real-world-ready NLP solutions.
Ensuring Reliable Retrieved Data
To ensure retrieved data is reliable, practitioners should implement:
- Robust source filtering, prioritizing authoritative and verifiable data sources.
- Automated fact-checking mechanisms to validate retrieved information before generation.
- Ongoing evaluation of retrieval algorithms, refining query processing to improve relevance and accuracy.
By integrating strict monitoring and validation protocols, RAG systems can be optimized to generate more trustworthy, contextually accurate responses, reducing the risk of misinformation in AI-driven applications.
Mitigating Model Drift
Continuous monitoring is essential to mitigate model drift, ensuring that NLP models remain accurate, relevant, and aligned with evolving knowledge and societal norms.
Fine-Tuned Models and Model Drift
For fine-tuned models, drift occurs when static training data no longer reflects current realities. This can lead to outdated or misaligned outputs, particularly in fields like healthcare, law, finance, and social policies, where knowledge evolves rapidly.
Addressing Model Drift
To address this, practitioners should implement:
- Periodic re-training with updated datasets to maintain relevance.
- Evaluation pipelines that flag inconsistencies and performance drops over time.
- Hybrid approaches that integrate RAG components to supplement static knowledge with real-time retrieval, reducing the risk of outdated responses.
By combining continuous monitoring, adaptive learning, and retrieval augmentation, NLP systems can remain resilient, scalable, and context-aware, ensuring their effectiveness in dynamic environments.
Ethical Considerations: Transparency in NLP
Ethical considerations surrounding misinformation and bias highlight the critical need for transparency in NLP models.
Why Transparency Matters
- Bias Mitigation: Without clear insights into how a model processes data, biases may go undetected, leading to unfair or discriminatory outcomes.
- Misinformation Control: In RAG models, retrieval sources influence outputs, making it crucial to track and validate information sources to prevent the spread of inaccurate or misleading content.
- Regulatory Compliance: Many industries, such as finance, healthcare, and legal tech, require explainability to meet compliance standards.
Strategies for Enhancing Transparency
- Explainable AI (XAI) Tools: Techniques such as SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-agnostic Explanations) help interpret model predictions.
- Audit Trails: Keeping logs of retrieved sources in RAG and training datasets in fine-tuning allows for accountability and bias detection.
- User-Controllable Retrieval in RAG: Allowing users to filter or select trusted sources enhances control over generated content.
Best Practices for Mitigating Challenges in Fine-Tuning and RAG
1. Comprehensive Model Evaluation
- Traditional performance metrics such as accuracy, precision, recall, and F1 score help gauge effectiveness in classification and retrieval tasks.
- Ethical evaluations should assess fairness, robustness against bias, and sensitivity to out-of-distribution inputs to prevent unintended harms.
- Stress-testing models under diverse conditions help uncover biases and vulnerabilities before deployment.
2. Diversifying Training Data (For Fine-Tuning)
- Expanding datasets to include diverse demographics, perspectives, and linguistic variations reduces the risk of reinforcing biases.
- Using data augmentation techniques helps balance underrepresented categories, preventing skewed model behaviour.
- Active learning approaches, where models are continuously refined with new, unbiased samples, can enhance adaptability over time.
3. Ethical Considerations in RAG Retrieval
- Ensuring retrieval systems prioritize credible, high-quality sources prevents the spread of misinformation.
- Implementing fact-checking mechanisms and confidence scoring helps flag unreliable outputs.
- Allowing human-in-the-loop validation ensures critical decisions (e.g., legal, medical) are reviewed before deployment.
Future Directions and Innovations in Fine-Tuning and Retrieval-Augmented Generation (RAG)
Hybrid Approaches: Combining Fine-Tuning and RAG
- Adaptive Learning Systems: Merging fine-tuned models with RAG-based retrieval mechanisms allows for models that retain domain expertise while dynamically accessing updated knowledge.
- Efficient Transfer Learning: Combining fine-tuned foundation models with RAG retrieval layers reduces the need for extensive retraining.
- Context-Aware Generation: Hybrid systems will enhance long-form text generation, knowledge-intensive applications, and conversational AI.
By integrating rigorous evaluation, diverse data strategies, and transparency-driven methodologies, researchers can refine fine-tuning and RAG implementations while minimizing risks. This proactive, ethical approach ensures NLP advancements serve their intended purposes responsibly, fairly, and effectively in a rapidly evolving AI landscape.



